
免费定制任何图像!清华团队突破性发现让AI绘画进入新纪元
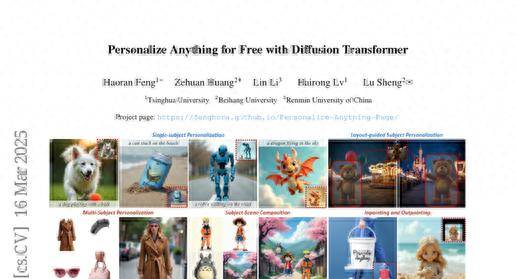
这项由清华大学冯浩然、北京航空航天大学黄泽桓(项目负责人)、中国人民大学李琳等研究团队共同完成的突破性研究发表于2025年3月,论文题目为《Personalize Anything for Free with Diffusion Transformer》。有兴趣深入了解的读者可以通过arXiv:2503.12590v1访问完整论文。
想象一下,如果你能让AI绘画工具完全按照你的想法,把你家的宠物狗、你最喜欢的杯子,或者任何你想要的物品,准确无误地画在任何你想要的场景中,会是什么感觉?以前,这样的定制化AI绘画需要大量的训练时间和计算资源,就像给AI老师上很多节私教课一样昂贵。但现在,中国研究团队找到了一个巧妙的方法,让这一切变得简单而免费。
这个被称为"Personalize Anything"(个性化一切)的技术框架,就像是给AI绘画工具装上了一个超级智能的"复制粘贴"功能。你只需要提供一张参考图片,AI就能把其中的物体准确地"移植"到任何新的场景中,而且效果好得惊人。更重要的是,整个过程完全免费,不需要额外的训练或微调。
研究团队发现了一个令人兴奋的秘密:新一代的AI绘画工具(被称为扩散变换器,或DiT)具有一种特殊的能力——它们能够将物体的外观特征和位置信息分开处理。这就像是一个智能的拼图游戏,你可以把一块拼图的图案保留下来,但把它的位置换到拼图的任何地方。这种能力为免费的个性化图像生成打开了全新的大门。
研究的创新之处在于发现了扩散变换器的"位置解耦"特性,并开发出了一套时间步自适应的令牌替换策略和补丁扰动技术。简单来说,他们找到了在AI绘画过程中的最佳时机来"植入"你想要的物体,既保证了物体特征的准确性,又确保了生成图像的多样性和自然度。
这项技术不仅能处理单个物体的个性化生成,还能同时处理多个物体的组合,甚至支持按布局指导生成、图像修复和扩展等高级功能。从实际应用角度来看,这意味着广告制作、内容创作、视觉故事叙述等领域都将因此受益。
一、揭开AI绘画的神秘面纱:为什么旧方法这么麻烦?
要理解这项研究的价值,我们首先需要了解传统AI个性化绘画面临的挑战。传统的个性化图像生成就像是训练一个专门的画师,每当你想要画一个新的物体时,都需要给这个画师提供很多该物体的样本图片,然后让他反复练习,直到能够准确地画出这个物体为止。
这种方法主要分为两类。第一类是"临时抱佛脚"式的方法,每次遇到新物体都要现场训练模型,通常需要几百次的迭代练习,耗时约30分钟的GPU计算时间。虽然效果不错,但时间成本很高,就像每次画画前都要重新学习一遍。第二类是"提前准备"式的方法,研究人员预先在大量数据上训练辅助网络,希望能够一劳永逸地解决个性化问题。但这种方法容易过度拟合训练数据,在面对真实世界的多样性时表现不佳。
近年来出现了一些"免训练"的方法,试图通过注意力共享机制来解决问题。这些方法的思路是让AI在生成新图像时,同时"关注"参考图像中的相关特征。然而,这些方法在应用到最新的扩散变换器架构时遇到了严重问题。
问题的根源在于扩散变换器采用了一种特殊的位置编码机制。传统的卷积神经网络(U-Net)通过卷积操作隐式地处理位置信息,而扩散变换器则明确地为每个图像块分配位置坐标。当研究人员尝试将传统的注意力共享方法应用到扩散变换器时,就像是在同一个座位上安排两个人坐下——参考图像和生成图像的对应位置会产生冲突,导致生成的图像出现重影和伪影。
研究团队通过定量分析发现,在扩散变换器中,生成图像对参考图像相同位置的注意力分数比在U-Net中高出723%,这说明扩散变换器对位置信息极其敏感。他们尝试了几种修复策略,比如移除参考图像的位置信息或将其移到非重叠区域,但都无法很好地保持物体特征的一致性。
二、意外的发现:简单替换竟然效果惊人
就在研究团队为传统方法的失效而苦恼时,他们做了一个看似简单的实验:直接用参考图像的特征块替换生成图像中对应区域的特征块。结果令人震惊——这种简单的"令牌替换"方法在扩散变换器中产生了高质量的物体重建效果,而在传统的U-Net架构中却会产生模糊边缘和伪影。
这个发现就像是意外找到了一把万能钥匙。研究团队意识到,扩散变换器的位置解耦特性是关键所在。在扩散变换器中,物体的语义特征和位置信息是分开存储的,就像是一个智能的标签系统,每个标签上既记录了"这是什么",也记录了"在哪里"。当进行令牌替换时,研究人员只替换了"这是什么"的信息,而保留了"在哪里"的信息,因此能够在新位置准确重建物体。
相比之下,传统的U-Net架构通过卷积操作将纹理和空间位置紧密绑定在一起,就像是一幅马赛克画,每个小块都与其周围的块存在复杂的依赖关系。当你试图替换其中的某些块时,就会破坏这种精细的依赖关系,导致图像质量下降。
这个发现不仅解释了为什么简单的令牌替换在扩散变换器中如此有效,也为各种图像编辑应用打开了新的可能性。无论是个性化生成、图像修复还是图像扩展,都可以通过这种统一的令牌替换框架来实现,而不需要复杂的注意力工程。
三、精心设计的"植入"策略:时机就是一切
虽然简单的令牌替换已经能够实现高质量的物体重建,但研究团队发现,如果在整个生成过程中都使用这种替换,会导致生成的图像过于僵硬,缺乏灵活性。就像是完全按照模板画画,虽然准确但缺乏创意。
为了解决这个问题,研究团队开发了一种"时间步自适应"的策略,巧妙地在生成过程的不同阶段采用不同的处理方式。这种策略的核心思想是在生成的早期阶段确保物体特征的一致性,在后期阶段增强灵活性和多样性。
具体来说,在生成过程的前80%时间里(早期阶段),系统采用令牌替换策略来锚定物体的身份特征。这个阶段就像是先打好草稿,确定物体的基本形状和关键特征。研究团队通过实验发现,这个阶段的令牌替换对于保持物体的身份一致性至关重要。
在生成过程的后20%时间里(后期阶段),系统切换到多模态注意力机制,让参考物体的特征与文本描述进行语义融合。这个阶段就像是给草图上色和添加细节,让最终的图像既保持了物体的核心特征,又能够灵活地适应文本描述的要求。
这种分阶段的处理策略非常巧妙。早期的令牌替换确保了生成物体与参考物体的高度相似性,而后期的注意力融合则允许系统根据文本提示对物体进行适当的调整和美化。这就像是一个经验丰富的画家,先用确定的笔触勾勒出物体的轮廓,然后用灵活的技法添加光影和色彩。
四、增加变化的巧思:补丁扰动技术
为了进一步增强生成图像的多样性,研究团队引入了"补丁扰动"技术。这个技术的灵感来自于一个简单的观察:如果完全按照参考图像来重建物体,虽然能够保证一致性,但可能会导致生成的图像过于单调。
补丁扰动技术包含两个核心策略。第一个策略是"随机局部令牌洗牌",在3×3的小窗口内随机打乱特征块的排列。这就像是轻微地摇晃一下拼图,让每个小块都稍微偏离原来的位置,但整体图案依然清晰可辨。这种局部的随机性破坏了过于刚性的纹理对齐,鼓励模型引入更多的全局外观信息。
第二个策略是"掩码增强",通过形态学操作(如膨胀和腐蚀)对物体掩码进行变形,或者手动选择强调身份特征的关键区域。这就像是稍微调整物体的边界,让系统有更多的灵活性来决定哪些细节需要严格保持,哪些可以适当变化。
这两种扰动策略的结合使用,让生成的图像在保持物体身份一致性的同时,具有了更好的结构和纹理多样性。研究团队的实验表明,使用补丁扰动技术后,生成的图像在身份保持和灵活性之间达到了更好的平衡。
五、无缝扩展:一个框架解决多种问题
"Personalize Anything"框架的另一个突出优势是其出色的扩展性。通过几何编程的方式,这个框架可以自然地扩展到多种复杂的应用场景。
对于布局引导的生成,系统只需要平移替换区域就能实现物体的空间重新排列。这就像是在画布上移动贴纸,你可以把同一个物体放在画面的任何位置。这种能力对于广告设计和产品展示特别有用,设计师可以轻松地调整产品在画面中的位置。
对于多物体个性化,系统通过顺序注入多个参考物体的特征来实现。每个物体都有自己的参考图像和目标区域,系统会依次处理每个物体,然后通过统一的多模态注意力机制协调所有物体与文本描述的关系。这就像是指挥一个乐队,每个乐器都有自己的旋律,但最终要和谐地融合在一起。
对于图像修复和扩展应用,系统会在逆向工程过程中加入用户指定的掩码条件,获得需要保留的参考特征。同时,系统会禁用扰动策略并将阈值参数调整到总步数的10%,这样可以最大程度地保留原始图像的内容,实现连贯的修复或扩展效果。
这种统一框架的设计哲学体现了研究团队的深刻洞察:看似不同的图像编辑任务,本质上都可以归结为在特定区域用特定内容替换原有内容的问题。通过巧妙的参数调整和策略选择,同一个框架就可以胜任各种不同的任务。
六、实验验证:数据说话的时刻
研究团队进行了全面的实验评估,证明了"Personalize Anything"框架的卓越性能。他们建立了三个层次的评估体系:单物体个性化、多物体个性化和物体-场景组合,并与10多种代表性方法进行了比较。
在单物体个性化任务中,研究团队使用了DreamBench数据集,该数据集包含30个基础物体,每个物体配有25个文本提示。他们将数据集扩展到750个测试案例,并使用多维度指标进行评估:FID用于质量分析,CLIP-T用于图像-文本对齐评估,DINO、CLIP-I和DreamSim用于身份保持评估。
实验结果显示,"Personalize Anything"在身份保持方面表现出色,CLIP-I得分达到0.876,DINO得分达到0.683,DreamSim得分仅为0.179(越低越好)。这些数字背后的含义是,生成的图像与参考物体高度相似,同时与文本描述的匹配度也很高。
特别值得注意的是,传统的基于优化的方法(如DreamBooth)虽然在某些指标上表现不错,但需要每个概念30分钟的GPU训练时间,而且有时会出现概念混淆的问题,比如将背景色彩错误地当作物体的特征。基于大规模训练的方法虽然不需要测试时调整,但在处理真实图像输入时往往难以保持细节的准确性。
在多物体个性化任务中,现有方法经常出现概念融合的问题,难以维持各个物体的独立身份特征,或者由于对物体间关系建模不当而产生破碎的结果。相比之下,"Personalize Anything"通过布局引导生成策略,成功地维持了物体间的自然交互,同时确保每个物体都保持其独特的身份特征。
在物体-场景组合任务中,与AnyDoor等方法相比,"Personalize Anything"生成的图像在主体与环境因素(如光照)之间表现出更好的一致性,避免了不协调的视觉效果。
七、用户研究:真实世界的认可
除了客观的数值评估,研究团队还进行了大规模的用户研究来验证方法的实际效果。他们邀请了48名年龄分布在15到60岁之间的参与者,每人回答15个问题,总共收集了720个有效反馈。
在单物体个性化任务中,用户需要从文本对齐、身份保持和图像质量三个维度选择最佳方法。结果显示,"Personalize Anything"在图像质量方面获得了70%的支持率,在身份保持方面获得了63%的支持率,在文本对齐方面获得了44%的支持率。
在多物体个性化任务中,"Personalize Anything"的表现更加突出,在图像质量方面获得了75%的支持率,这表明用户认为该方法生成的多物体图像看起来更加自然和协调。
在物体-场景组合任务中,研究团队用场景一致性替代了文本对齐指标,以评估物体与场景的协调程度。结果显示,"Personalize Anything"在图像质量方面获得了73%的支持率,在身份保持方面获得了66%的支持率,这证明了该方法在复杂场景合成方面的优势。
用户研究的结果不仅验证了客观评估的结论,也说明了该方法生成的图像确实符合人类的视觉偏好和质量标准。
八、深入的消融实验:解析成功的关键因素
为了更好地理解"Personalize Anything"框架中各个组件的作用,研究团队进行了详细的消融实验。这些实验就像是拆解一台精密机器,逐一检查每个零件的功能。
首先,他们系统性地研究了时间步阈值τ的影响。实验结果显示,当τ设置为总步数的90%时,生成的图像与参考物体几乎完全相同,但缺乏灵活性。随着τ值逐渐降低到80%,系统在保持高身份相似性(CLIP-I得分0.882)的同时,获得了更好的文本对齐能力(CLIP-T得分0.302)。
当τ继续降低到70%时,生成的物体开始过度依赖文本描述,身份特征的保持程度显著下降。这个实验清楚地表明了80%这个阈值的合理性——它在身份保持和生成灵活性之间找到了最佳平衡点。
补丁扰动策略的效果同样显著。在没有扰动的情况下,生成的物体在结构上与参考物体高度相似,但可能显得过于刚性。加入补丁扰动后,生成的图像在保持身份一致性的同时,展现出更好的结构和纹理多样性。实验数据显示,使用扰动策略后,CLIP-T得分从0.302提升到0.307,这表明生成的图像更好地融合了文本描述的要求。
九、实际应用展示:从实验室到现实世界
"Personalize Anything"框架的实际应用潜力通过一系列令人印象深刻的示例得到了充分展示。在布局引导生成方面,用户可以轻松地将同一个物体放置在图像的不同位置,就像是在数字画布上自由移动贴纸一样。这种能力对于广告设计师来说特别有价值,他们可以快速尝试不同的产品布局方案。
在图像修复应用中,系统能够无缝地填充图像中的缺失区域,保持与原始内容的高度一致性。无论是去除不需要的元素,还是修复损坏的区域,系统都能产生自然流畅的结果。
在图像扩展应用中,最令人惊叹的是系统能够合理地扩展图像边界,创造出与原始图像风格一致的新内容。这就像是让AI画家续写一幅未完成的画作,既要保持原有的风格和主题,又要合理地扩展画面内容。
视觉故事叙述是另一个引人入胜的应用场景。通过在不同的场景中重复使用相同的角色或物体,创作者可以构建连贯的视觉故事。这种能力对于儿童读物插画、广告系列创作和教育内容制作都具有重要价值。
十、技术细节与实现:让理论变成现实
"Personalize Anything"框架基于开源的HunyuanDiT和FLUX.1-dev模型实现。系统采用50步采样策略,配合3.5的无分类器指导权重,能够生成1024×1024分辨率的高质量图像。令牌替换阈值τ设置为总步数的80%,这个参数是通过大量实验优化得出的最佳值。
实现过程中的一个关键技术挑战是如何准确地获取参考图像的特征表示。研究团队采用了流逆转技术来从参考图像中提取不含位置编码的特征令牌,同时获取对应的物体掩码。这个过程就像是对图像进行"逆向工程",提取出最纯粹的语义信息。
另一个重要的技术细节是多模态注意力机制的实现。在生成过程的后期阶段,系统需要协调参考物体特征、生成图像特征和文本嵌入之间的关系。这个过程通过精心设计的注意力计算来实现,确保最终生成的图像既符合参考物体的身份特征,又满足文本描述的要求。
补丁扰动策略的实现相对简单但效果显著。随机局部令牌洗牌在3×3窗口内进行,而掩码增强使用5像素内核的形态学操作。这些看似简单的操作却能有效地打破过度刚性的特征对齐,为生成过程注入适度的随机性。
研究团队还特别注意了系统的计算效率。与需要每个概念训练30分钟的传统方法相比,"Personalize Anything"的推理过程只需要几秒钟,这使得它在实际应用中具有明显的优势。
这项研究最终建立了一个完整的技术生态系统,从理论发现到实际应用,从单一功能到多场景支持,展现了从学术研究到实用工具转化的完整路径。研究团队不仅解决了一个具体的技术问题,更重要的是为整个领域提供了新的思路和方法。
说到底,这项研究的真正价值不仅在于它解决了个性化图像生成的技术难题,更在于它揭示了扩散变换器这一新兴架构的内在潜力。通过简单而优雅的令牌替换策略,研究团队证明了有时候最简单的解决方案往往最有效。这种"大道至简"的哲学可能会启发更多类似的技术突破。
从实用角度来看,这项技术将大大降低个性化内容创作的门槛。无论是小企业主想要为自己的产品制作广告图片,还是内容创作者想要制作个性化的视觉作品,都可以通过这种免费的方法实现专业级的效果。这种技术民主化的趋势,正在让AI工具变得更加普惠和实用。
更有趣的是,这项研究可能预示着AI图像生成领域的一个重要转折点。随着扩散变换器架构的不断发展和优化,我们可能会看到更多基于这种位置解耦特性的创新应用。也许在不久的将来,我们就能看到更加智能、更加灵活的AI绘画工具,让每个人都能成为数字艺术的创作者。
有兴趣深入了解技术细节的读者,可以通过arXiv:2503.12590v1访问完整的研究论文,其中包含了更多的技术实现细节和实验数据。
Q&A
Q1:Personalize Anything是什么?它能做什么? A:Personalize Anything是由清华大学等机构开发的免费AI图像定制框架,它能让用户仅通过一张参考图片,就让AI准确地在任何新场景中重现该物体,无需训练或付费。支持单物体、多物体个性化,以及图像修复扩展等功能。
Q2:这个技术会不会取代传统的图像设计工作? A:目前不会完全取代,但会大大提升设计效率。它更像是给设计师提供了一个强大的辅助工具,能快速实现创意构思,让设计师把更多精力投入到创意本身而非技术实现上。小企业和个人创作者将特别受益。
Q3:普通人如何使用这项技术?有什么要求? A:目前该技术基于开源的HunyuanDiT和FLUX模型实现,研究团队已公开相关代码。普通用户需要一定的技术基础来部署使用,但随着技术成熟,未来可能会有更友好的产品化应用出现,降低使用门槛。