
重创美股后,DeepSeek发第二弹,文生图模型力压OpenAI

出品|搜狐科技
作者|郑松毅
除夕惊喜大放送,DeepSeek再发强悍新模型!
北京时间1月28日凌晨,近期爆火的国产大模型“黑马”DeepSeek,发布了全新开源多模态模型Janus-Pro,正式进军文生图领域。
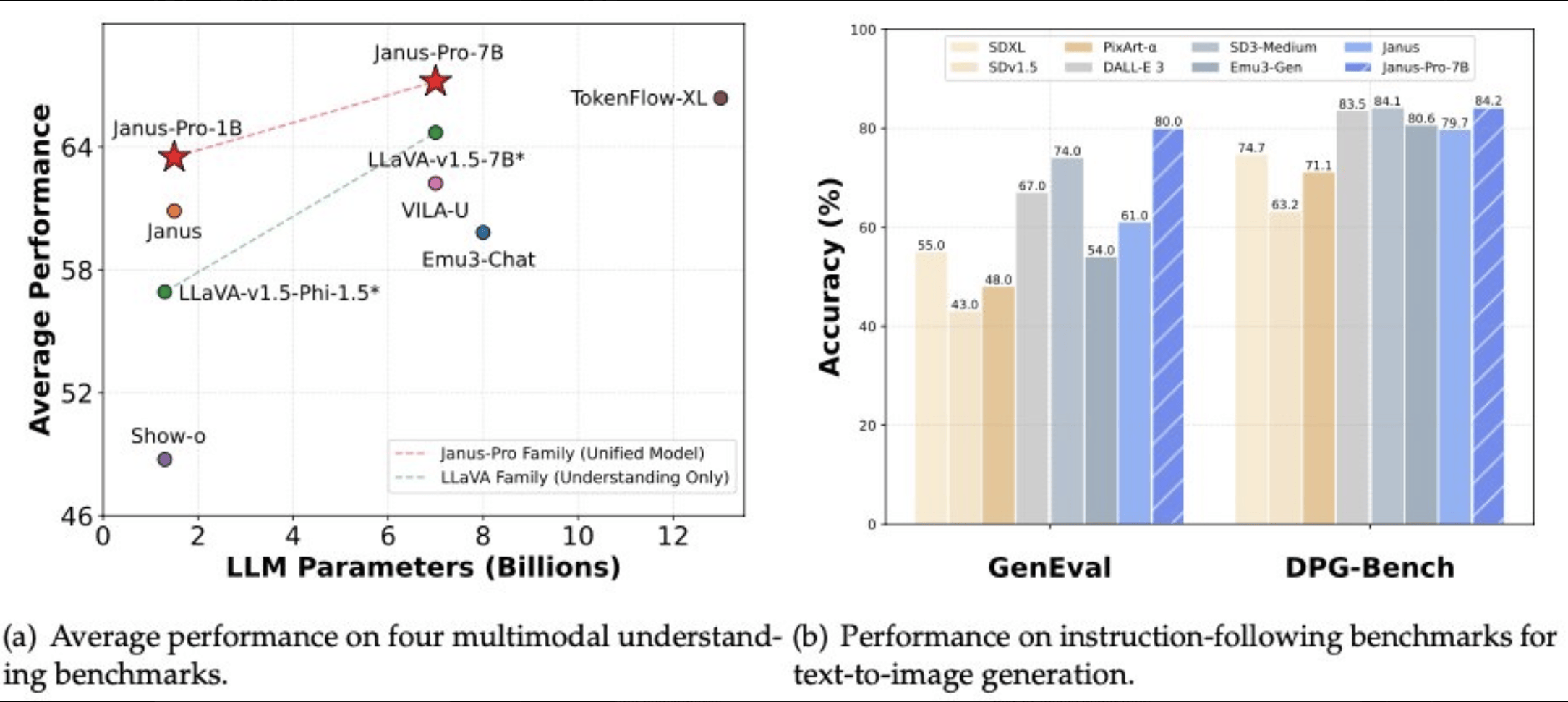
DeepSeek介绍,模型Janus-Pro为去年11月发布的模型JanusFlow升级版本,拥有15亿和70亿参数规模, 意味着这两个模型具备在消费级电脑上本地运行的潜力。
相较于前一代模型,Janus-Pro的主要提升在于优化了训练策略、扩展了训练数据,从而在图像理解和生成方面取得了显著进步。
从测试图来看,新模型Janus-Pro的生图稳定性的确增强了不少,对目标人物和物体画像能够更加生动呈现,色彩饱和度也处理得更加得当。

在识图方面,Janus-Pro也能根据给定图像说得头头是道。

值得一提的是,在文生图GenEval和DPG-Bench基准测试中,Janus-Pro-7B模型已经成功击败了Stable Diffusion和OpenAI的DALL-E 3等热门模型。
网友看后直呼,“大家还没来得及从R1模型带来的震撼反应过来,只有70亿参数规模的多模态模型Janus-Pro又让人不可思议,而且还是开源的。新游戏开始了!”
目前,Janus系列模型均已在GitHub平台实现开源,供开发者和研究人员使用,旨在推动文生图生态的进一步发展,并促进相关应用的研究。
新模型,“新”在哪?
简单来说,在Janus-Pro身上,DeepSeek用到了新颖的多模态模型训练框架“视觉编码解耦”,通过将视觉编码分离为“理解”和“生成”两条路径,提升了模型在不同任务中的适配性与性能。
这种“解耦”,解决了编码器在理解和生成任务中角色冲突的问题,相当于让编码器更专心地完成各自任务,从而增强图像理解和生成的稳定性。
数据方面,Janus-Pro通过添加7200万张高质量合成图像,实现了真实数据与合成数据比例达到1:1,在视觉生成方面输出更具吸引力和稳定性的图像。此外,该模型还参考了DeepSeek VL2并增加了约9000万个样本进行多模态理解的训练数据。
训练方面,DeepSeek在训练步骤中根据特定比例混合所有数据类型,使用HAI-LLM平台进行训练和评估。
整个训练过程在1.5B/7B模型的16/32个节点的集群上花费了7/14天,每个节点配备了8个英伟达 A100 GPU。
令硅谷和华尔街“震颤”
短短一周内,DeepSeek接连发布的R1与Janus-Pro模型,显然震惊到了处在AI技术前位的美国,且给到了不小的压力。
截止1月27日晚,DeepSeek应用下载量已超越ChatGPT,登顶苹果美国区免费App下载排行榜。
长日来,在大语言模型领域,ChatGPT系列、Gemini全家桶、Claude等模型身处赛道领先地位。而在多模态模型领域,Stable Diffusion、DALL-E 3等热门模型抢尽风头。
如今,DeepSeek已分别在语言模型和多模态模型领域,对昔日海外热门模型实现赶超。用创新思路,打破了“中国AI只能跟随”的刻板印象。
从打发策略来看,DeepSeek系列模型主打的就是好用且实惠,素有“AI界的拼多多”之称。DeepSeek模型拥有与GPT-4o比肩的性能,但价格只是其的1/20。
DeepSeek“不可思议”的成绩,同样震慑到了美国股市,让一众美国AI“明星股”纷纷出现跌落表现。
截止周一收盘,在满屏“DeepSeek是什么”的疑问中,纳斯达克综合指数跌3.07%,报19341.83点;标准普尔500指数跌1.46%,报6012.28点。
其中,英伟达周一收跌16.97%,市值蒸发近5900亿美元,相当于跌出了多于3个AMD,刷新美国金融史纪录。
福布斯富豪榜显示,英伟达创始人黄仁勋的个人财富,也在周一蒸发超208亿美元。
此外,欧美科技股势合计蒸发万亿美元市值,英伟达、博通、台积电等巨头美股盘前纷纷跌超10%。
“中国不可能永远只是跟随”
这句振奋人心的发言,出自DeepSeek创始人梁文锋的最新回应。
他表示,“我们经常说中国AI和美国有一两年的差距,但真实的gap(差距)在于原创和模仿,如果这个不改变,中国永远只能是追随者,所以有些探索是逃不掉的。”
“过去三十年的IT浪潮里,中国基本没有参与到真正的技术创新里,我们已经习惯了‘摩尔定律’从天而降,等着用现成的硬件和软件。但我认为随着经济发展,中国也要逐步成为技术的‘贡献者’。”
在这场全球AI竞赛中,DeepSeek没有选择搭已有模型架构的“便车”,而是选择了创新。用新颖的模型训练架构,做了更多的尝试。
对于未来,梁文锋和团队想的很清楚,“要参与到全球创新浪潮中去,而不是习惯于拿别人的创新过来,做应用变现。”
澜舟科技创始人&CEO周明发文表示,“DeepSeek从技术突破到APP登顶,不仅成功改写了AI行业发展的轨迹,更有力地宣告了大模型轻量化的重要意义和所谓的Scaling Law的终结。”
“这是技术极致主义的胜利,更是中国人才智慧与创造力的胜利。那些对OpenAI亦步亦趋,拿Scaling law忽悠,瞧不起中国人才的所谓大咖可以回去洗洗睡睡了。”
Meta创始人兼CEO马克·扎克伯格,同样看好中国AI技术发展。在DeepSeek模型发布后,他表示,“DeepSeek的大模型非常先进,中国正在全力冲刺,美国科技行业虽然暂时领先,但两者差距很小。”
此外,AI科技初创公司Scale AI创始人亚历山大·王也公开表示,“过去十年来,美国可能一直在人工智能竞赛中领先于中国,但DeepSeek的AI大模型发布可能会‘改变一切’,尤其是在开源领域。”